分类

串行
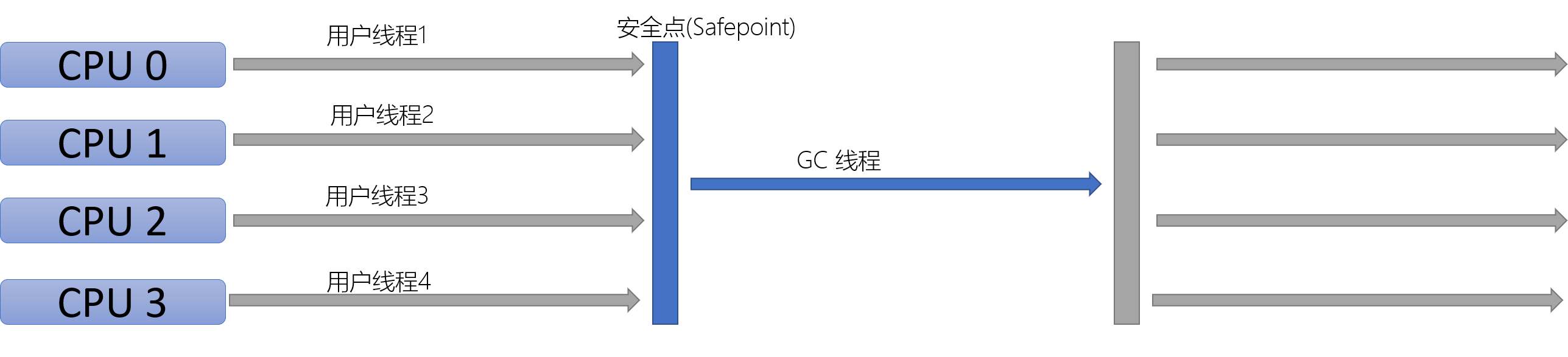
不仅仅说明它只使用一个CPU或一条收集线程去完成垃圾收集工作,更重要的是在它收集垃圾时,必须暂停其他所有工作线程,知道它收集结束。(Stop-The-World)
Serial 收集器
适用于新生代垃圾收集,采取复制算法,暂停所有用户线程
Serial Old 收集器
适用于老年代垃圾收集,采取标记-整理算法,暂停所有用户线程
吞吐量优先
Parallel Scavenge 收集器
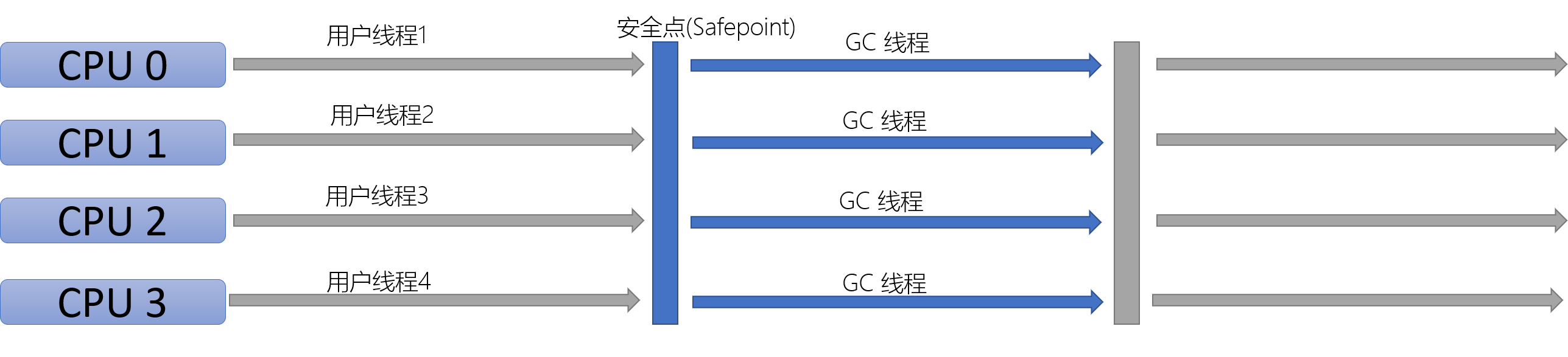
适用于新生代垃圾收集,采取复制算法,暂停所有用户线程
Parallel Old 收集器
适用于老年代垃圾收集,采取标记-整理算法,暂停所有用户线程
+XX:MaxGCPauseMills 控制最大垃圾回收停顿时间
+XX:GCTimeRatio 垃圾收集时间占比1/(1+ratio)
+XX:+UserAdaptiveSizePolicy GC自适应调整策略
响应时间优先
CMS(Concurrent Mark Sweep)收集器
这是一种以获取最短回收停顿时间为目标的收集器。该收集器基于标记-清除算法实现。

初始标记(CMS initial mark): 仅仅只是标记一下GC Roots能直接关联到的对象,速度很快
并发标记(CMS concurrent mark): 进行GC Roots tracing
重新标记(CMS remark):修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录
并发清除(CMS concurrent sweep)
优点:
1.并发收集
2.低停顿
缺点:
1.对CPU资源非常敏感
2.无法处理浮动垃圾(Floating Garbage),可能出现Concurrent Mode Failure导致另一次Full GC
3.基于标记-清除算法可能产生空间碎片
-XX:+UserCMSCompactAtFullCollection 用于碎片整合
-XX:CMSFullGCsBeforeCompaction=size 用于执行多少次不压缩的Full GC后,跟着来一次碎片整合,默认为0
G1
G1(Garbage First)收集器
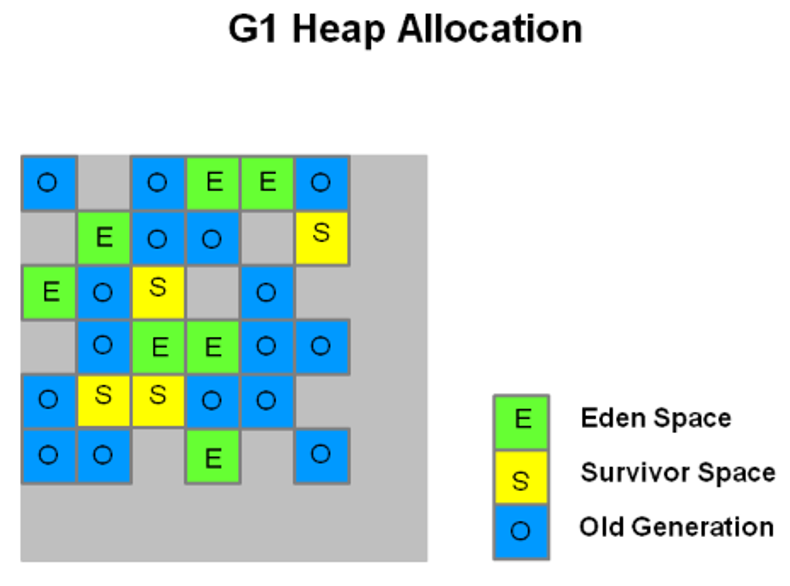
G1内存模型:
将整个Java堆划分为多个大小相等的独立区域(Region),每个Region被标记了E、S、O和H(巨型对象:humongous object,用于容纳大小为标准区域50%或更大的对象)。
堆分为大约2000个Region,每个Region最小为1Mb,最大为32Mb。
-XX:G1HeapRegionSize可以设置Region大小。
Young GC:
发生在年轻代的GC算法,一般对象(除了巨型对象)都是在Eden Region中分配内存,当所有Eden Region被耗尽无法申请内存时,就会触发一次Young GC,活跃对象会被拷贝到Survivor Region或者晋升到Old Region。
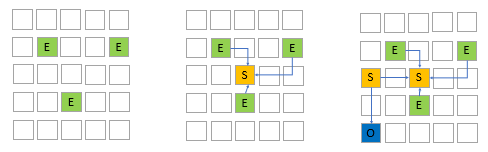
Mixed GC:
当越来越多的对象晋升到老年代Old Region时,为了避免堆内存被耗尽,虚拟机会触发Mixed GC,除了回收整个Young Region,还会回收一部分的Old Region。
大致步骤

1.并初始标记( Initial marking)
仅仅只是标记一下GC Roots能直接关联到的对象,并且修改TAMS(Next Top at Mark Start)的值,会触发STW,耗时很短
2.并发标记(Concurrent marking)
进行GC Roots tracing
3.最终标记(Remark)
修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,
虚拟机将这段时间对象变化记录在线程Remembered Set Logs,在最终阶段需要把Remembered Set Logs的数据合并到Remembered Set中
4.复制清理(Copying/Cleanup)
只选择垃圾较多的区域